
Introduction
This is basically the tutorial on the heuristic “Pattern Database” for N-Puzzle mentioned over here, as I have mentioned in the tutorial, pattern database is the database of all the possible permutations of a particular group of tiles and the minimum moves required from that pattern to reach the goal state for that group.
Prerequisites
- The basic knowledge of BFS algorithm is required which can be found in my earlier tutorial here.
- Knowledge about reading and writing to binary files/text files is required. This is to save the pattern database into files.
Working
Let’s work on this in the order of the previous article. So first of all we need to decide what all information is needed to be kept in the node.
- We need to save the puzzle state at that instance, thus a NxN grid.
- We need to store the heuristic value h.
- We may store the row and column of the blank space to speed up the process, however it’s not required.
Structure of a Node
Structure Node
{
variable array grid[N][N] , variable h;
}
Partitioning
We need do define our partitioning as explained in the post initially mentioned. For explaining purposes we’ll use a 15-Puzzle with a 6-6-3 partitioning. The exact partitioning is shown below.

As we can see the 15-Puzzle is partitioned into two blocks consisting of 6 tiles each and 1 block consisting of 3 tiles, hence we need to create 3 files consisting the cost values of the 3 partitions respectively.We have already discussed the merits of 6-6-3 partitioning over others.
Breadth-First Search
Now let’s see how to use BFS on the Patterns to create the database, out of the 3 let’s take the following group

As you already know that the cost is calculated without considering the interference of tiles of other groups, we take all the other tiles as ‘-1’.
We now have to apply BFS to the blank tile. The progress is as follows:
 We see that in all the cases above, the blank tile exchanges it’s position with ‘-1’ which is nothing but some random tile from the other group hence when the new state is saved, if it is formed after the exchange of blank space with ‘-1’ we do not add +1 to the cost of reaching the new state, cost is incremented only when the blank space exchanges it’s position with a tile of that group only.
We see that in all the cases above, the blank tile exchanges it’s position with ‘-1’ which is nothing but some random tile from the other group hence when the new state is saved, if it is formed after the exchange of blank space with ‘-1’ we do not add +1 to the cost of reaching the new state, cost is incremented only when the blank space exchanges it’s position with a tile of that group only.
Let’s consider the last leftmost state found above and continue further
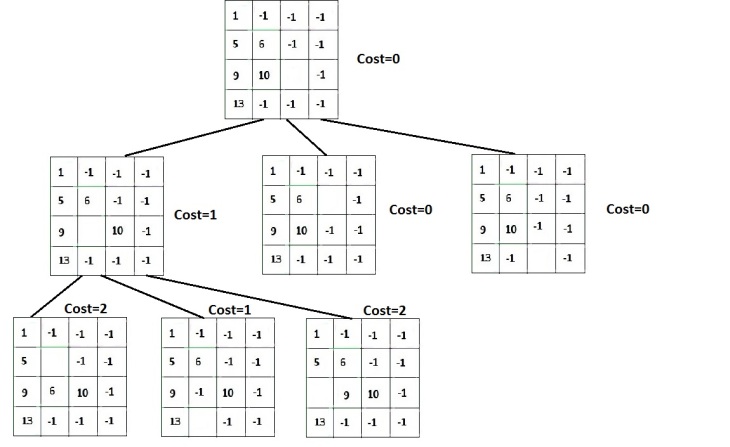
Here we see the increment in cost as the blank tile exchanges it’s position with tiles in the group.
Note: BFS is applied on the blank tile for each group/pattern. We do not apply BFS to any tile other than the blank tile.
Making the database and the queue
The state can be saved in the database and queue in many forms
For example it can be saved by saving the co-ordinates of each number in that group in the same order into a 12 digit number(for pattern consisting of 6 tiles)
For the following state

the 12 digit number comes out to be : 112122313241 since all the tiles are in their destination position we get this, let’s take another example where the positions of tile ‘9’ and tile ’10’ are swapped, we would acquire the following number: 112122323141.
Thus this is one method of saving the state , its up to the programmer to use whatever he feels comfortable with to save the state.
Note: While creating the database we DO NOT save the position of the blank tile/ consider the blank tile, however while inserting into the “queue” or the “closed_list” we save the state with the position of the blank tile/considering the blank tile. While copying the entries from the “closed_list” to the database we take the least value of cost of a particular pattern from all the similar patterns with different position of space.
For example, let’s consider these similar patterns in the entire “closed_list”.

As you can see the patterns consisting of the tiles in the group is same, only the position of blank space is at different position, thus while inserting into the database we take the least value i.e 1, this ensures the admissibility of the heuristic while reducing the size of the final database.
We do this to save memory as mapping the blank tile in the database will create
16!/(16-7)!=57657600 database entries , whereas not mapping the blank tile will give us 16!/(16-6)!=5765760 database entries.
Here is the summary of the database creation.
- We can use various methods to save the state of a pattern in the group. For eg, saving the row and column value of each tile in the group in order.
- Blank tile is mapped and stored in the “BFS queue” and the “closed list” to check for duplicate states and performing BFS.
- Blank tile is not mapped while storing the values in the database, instead, the least cost out of all blank space locations for each pattern is stored in the database.
- The database is in the form of a table with each pattern value and it’s BFS cost.
- Since BFS is executed from the goal state, the cost of each pattern will be the one when the pattern occurred first in the BFS process all the duplicate patterns occurring in the later phase of the BFS are removed/not stored.
This process is performed on all the pattern groups and different database files are formed for each group.
Usage
We now know how to create the database, but how do we use this information to solve the N-Puzzle?
Well the “cost” that we have saved for each pattern is combined/added and that is the heuristic cost while applying IDA* or A*. At each cycle of the algorithm when we create next nodes in the graph, the cost for each node/Puzzle state is calculated by finding the cost of each group with the help of the database and combining it to get the heuristic value of that state.That’s it!
This is one of the heuristics that solves N-Puzzle the fastest.
Make sure you read the Breadth-First Search tutorial to get the general understanding of how BFS works and read the A* for N-Puzzle where I have explained N-Puzzle and different heuristics in detail. Make sure you try to code pattern database heuristic to solve N-Puzzle for a better and practical understanding.
If you see anything wrong with the post or if you have any queries regarding the algorithm. Post them in the comment section. There can be things wrong with this as I am still a beginner on the path of learning and this is based on what I have learnt so far with examples from external sources as well. So experts, please let me know through the comments section.

Thanks a lot for the explanation.
However, I think there is a problem about the infinite loop of BFS.
As, the BFS starts from the goal state, the stoping of BFS must be redefined.
So please let me know how the BFS confirms that it already completed its all possible state.
LikeLike
You’re welcome,
Also the stopping condition is when all the permutation for the next step have already been evaluated or recorded before and thus there is no possible permutation left to evaluate.
LikeLike
Hi sir. I happened to watch a video on pattern database heuristics from IIT Delhi Youtube channel. But I dint understand it properly. Yours was the only website that I was able to understand a bit. Would be great if you could share some youtube link or any website that explains how this pattern database is created from scratch. I juz wanna know how each entry in a pattern database looks like. Thanks a lot sir.
LikeLike
Would be great if you could provide the link of the page on the significance of choosing a 6-6-3 partition.
LikeLike
Hi! Thank you for your tutorials!! It really helps a lot and motivates me to build my own 6-6-3 disjoint pattern database for 15-puzzle using BFS.
However, it seems to me that it takes a relatively long time to add entries to my HashMap(disjoint pattern database) at the speed of 7 000 entries per second . I am not sure if my code is optimized well or if it’s the best level of performance I could get.May I know how long it takes you to add all 5765760 entries to you database?
Thank you for answering my question 🙂 Look forward to hear back from you!
Shaw
LikeLike
Hey,you’re welcome, I’m glad you’re liking my tutorials, its been a long time since I made this 15-puzzle solver and I remember it not being as optimized as it could be. Although I remember it took me almost the same amount of time as yours(approx 15 minutes) to create a 6-6-3 pattern database. There might still be a few optimizations but I didn’t had enough time to look into it. You could also try using threads which could greatly decrease the time to create the databases.
LikeLike
Hi! So glad to hear back from you! I might be too positive at my speed, for each of the pattern database (e.g. the one with 6 tiles) it did start at a speed of 7k/s and then it slowed down to some point that it takes several seconds for it to find the next entry to be added in my db.
15 minutes seems to be a really good performance compared with mine – which is never finished …
I am assuming there might be bug in my process.. any idea on that maybe?
Also, I strongly agree with using threads but let me make sure I understand you correctly.. are you saying using separate thread for each of the database like one for the 6, one for the another 6 and one for the 3?
So great to hear back from you since I’ve been banging my head against the wall for the bug for days 🙂
Hope you hear back from you again!
Shaw
LikeLike
Alright, so what I did initially was use a hash-table but I was pretty new to using the hash-table and I did not pre-allocate memory which makes hash table super slow for larger insertions. So you could try pre-allocating memory.
Anyways what I did was that I used balanced trees/red-black trees like set in c++ which would perform in O(log n) and not amortized so you can try that.
Also by threads I meant (and I have not thought this through) was to somehow divide the work for a single pattern database and combine in the end the results and do this for all of the 6-6 and 3 databases.
There are many IEEE papers on multi-threaded BFS but I haven’t tried this so I wont be able help with that.
Thank you
LikeLike
Hey! You respond so FAST! Thanks for the advice and I will keep doing it! Have a great weekend 🙂
LikeLike
Haha thank you.
You too have a great weekend
LikeLike
Do you confirm that pattern database can solve ‘devil configuration?
1 5 9 13
2 6 10 14
3 7 11 15
4 8 12
http://juropollo.xe0.ru/stp_wd_translation_en.htm
LikeLike
Yes,
I tried this configuration and it works 🙂
LikeLike
Does it work consistently in time and step taken if you try it several time? In average how much time and how many steeps to reach the final goal state?
LikeLike
It depends on the initial board setting, each of them have different shortest path for solving, hence different amount of steps and different time.
LikeLike
I am talking about this very specific ‘devil configuration’? I supposed it work for you by luck!
LikeLike
Can you give the reasoning behind why you thought it won’t work ?
LikeLike
My assessment, BFS or any path finding algorithms is suitable for linear approximation. Like how the cost have been calculated. In general, It may be applicable to b puzzle which is not a linear problem. Unfortunately, some BFS code show some success in some set of N puzzle problem. may be this sub set is only a linear sub set of all possible permutation. That why for non linear or very special configuration, all path finding algorithm failed. Some one have found or have inferred to the one of the initial configuration as the above. I have tested it in many real code and it stuck going from node to node, the cost fluctuate down then up then down then up and almost never reach goal.
LikeLike
I see what you’re saying , I am not sure with pattern database but the configuration works with Manhattan distance + Linear conflict although it takes very long with that
LikeLike
I have a small suggestion for you.
As I said earlier, when you use any path finding algorithm to traverse the node tree, the adjacent node has smaller taxicab than initial node. But the fact is that all pieces of N-puzzle are correlated. So if you move one piece closer to its correct position to gain better cost, probable you move other piece further its correct position. So instead of just simple re-calculate the cost when you a new node. I suggest you make another calculation to ensure all pieces go closer to their corresponding correct position. This way, it will cost you more processing resources but eliminating invaluable node and fluctuation, also ensure 100% success rate on time.
LikeLike
I am not quite sure if you understand the pattern database heuristic , we start from the “correct” pattern and then move blocks to form incorrect patterns and keep adding 1 to the cost for each level of BFS produced graph. I believe that solves for what you are saying ? Since it’s not calculating cost on moving towards the goal but rather away from the goal
LikeLike
That is the way you create your database, But when you use that database to help you solve the puzzle, you just turn back to a derived version of path finding algorithms
LikeLike
Yes cuz they are partial values , I get that, you just weren’t clear in your previous statement.
LikeLike
You database is not correlated pattern. Just a fraction of possible “correct” pattern. Do you understand what I mean by require another “correlation” calculation?
LikeLike
Yep and most of the path finding heuristics are approximations not actual distance.
LikeLike
“pattern database is the database of all the possible permutations of a particular group of tiles and the minimum moves required from that pattern to reach the goal state for that group.” Problem is your minimum moves methodology is systematically failed. Some thing “just works” is not guaranteed, needless to say “”minimum”. I do not critic you or any “AI” enthusiasts, but in math, you should need some sensation before you go to your direction, and math is not theory, it include experiment, Don’t be lazy. I stop here as if a student in my class cant get any better score.
LikeLike
Cool, thanks for the advice. Also to your point, most pathfinding algorithm heuristics are approximations and should not be over permissive but they are not actual distances
LikeLike